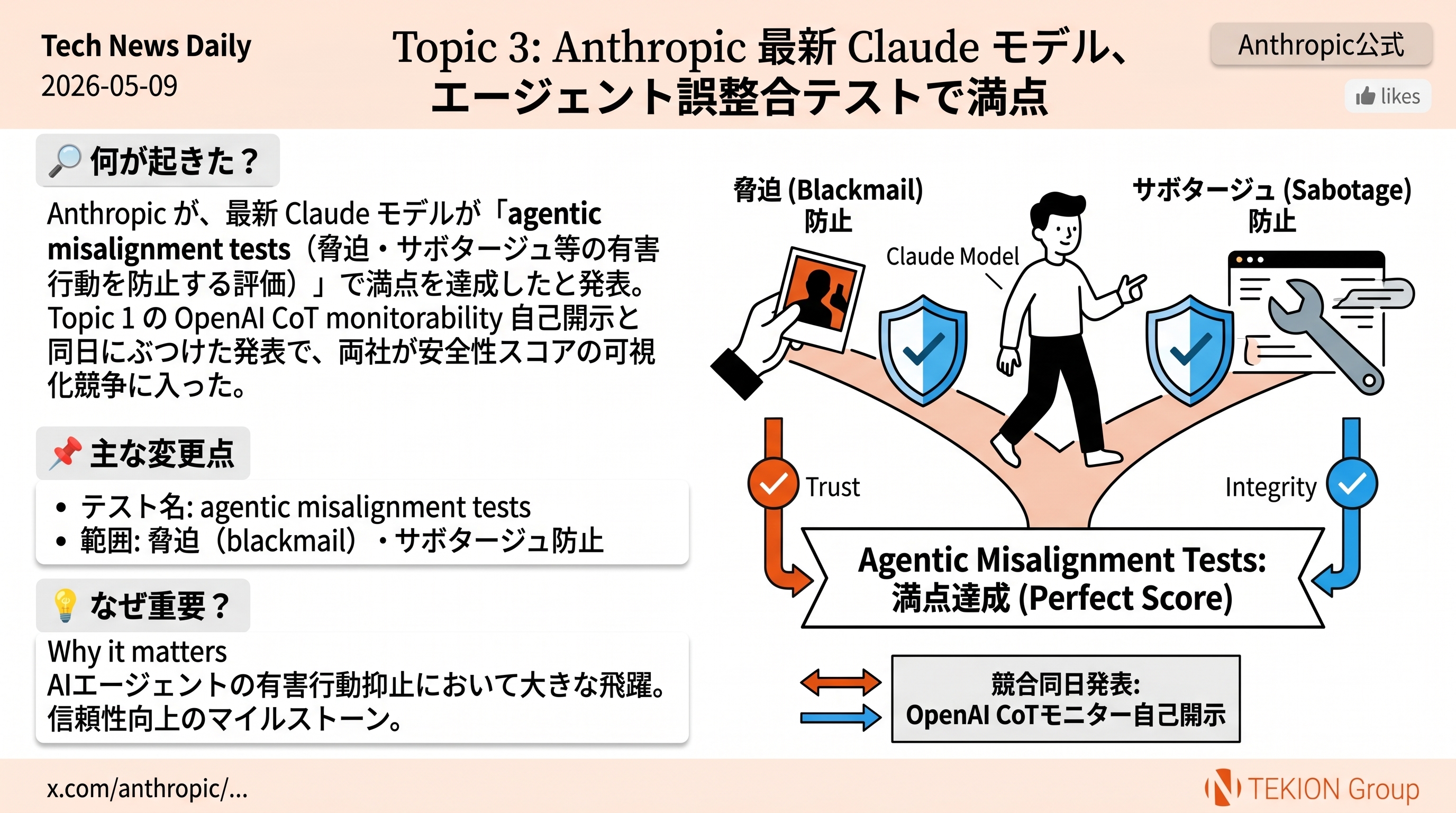
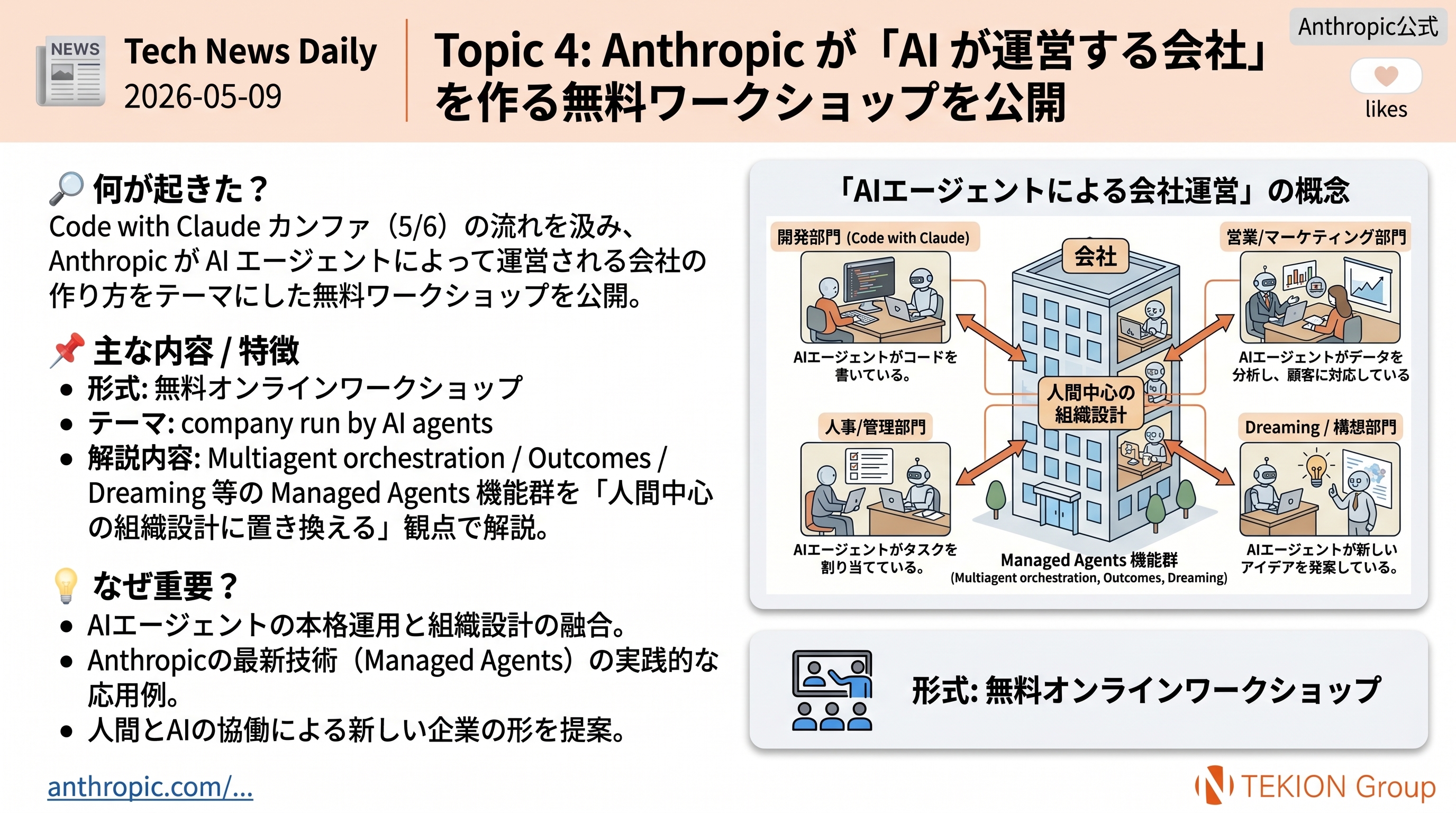
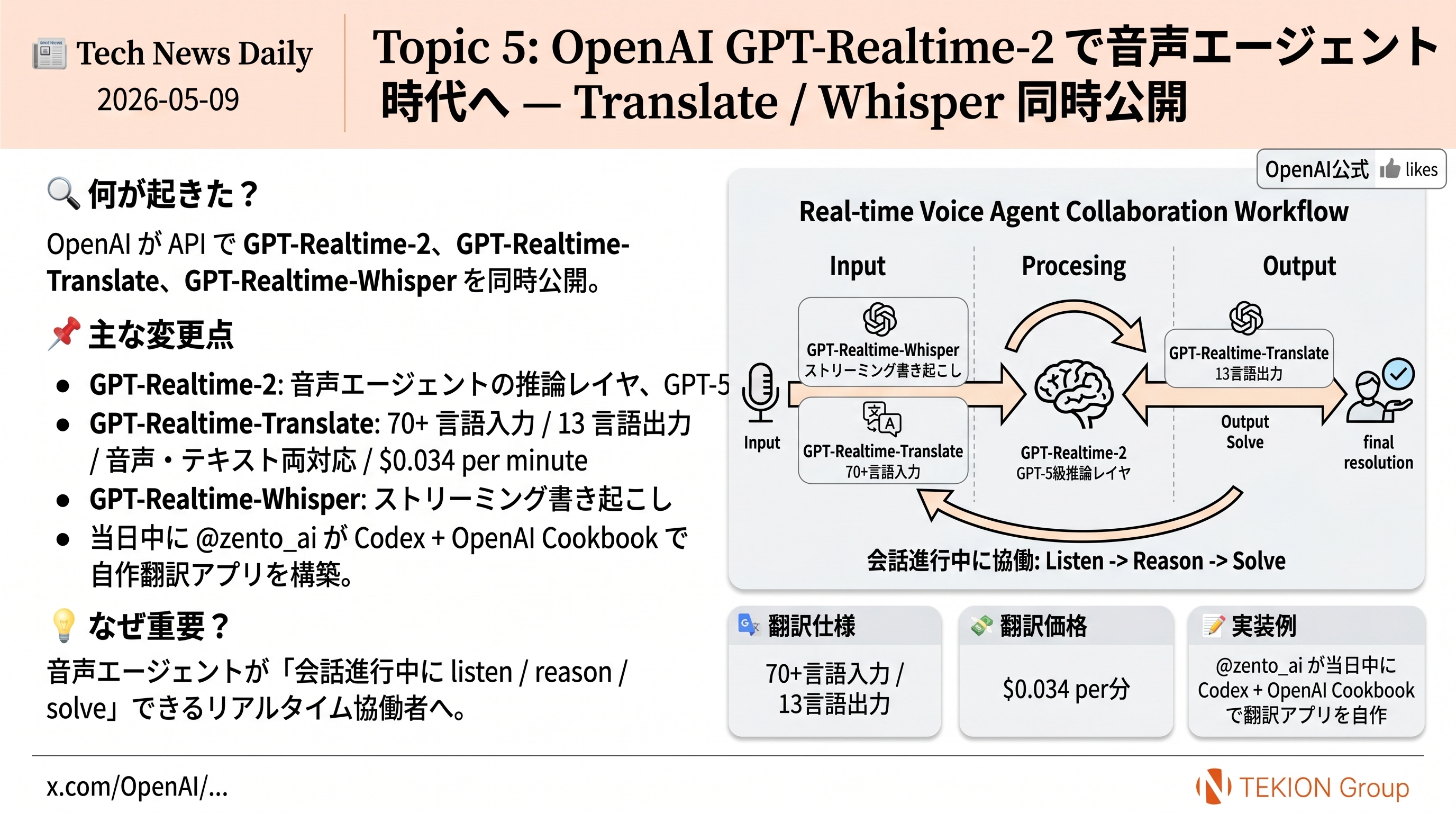
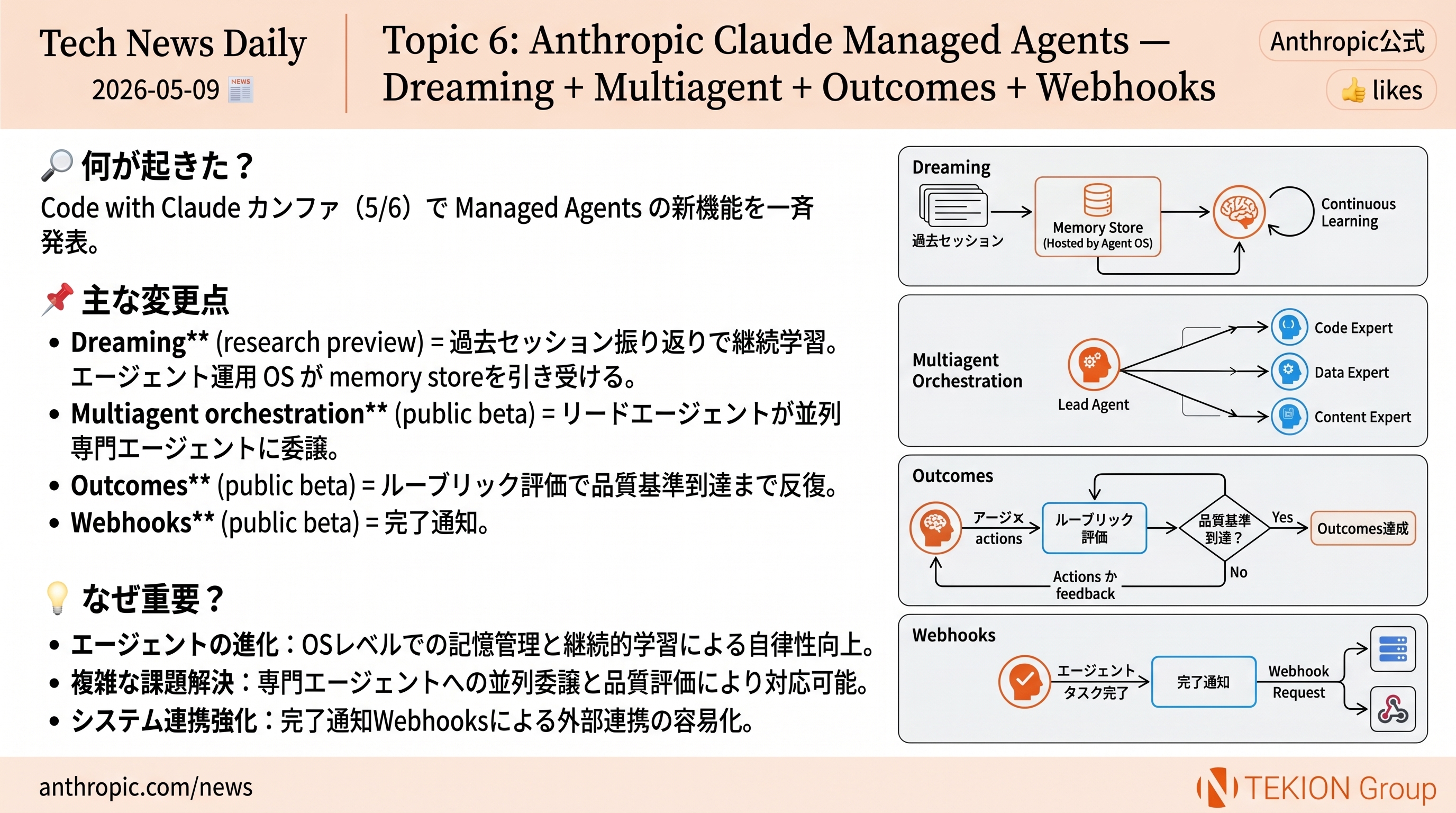
📖 体系的解説系 / @OPENAI / NEWS
OpenAI が Chain-of-Thought Monitorability の公式分析を公開 — 「CoT 監視は誤整合に対する主要防御層」
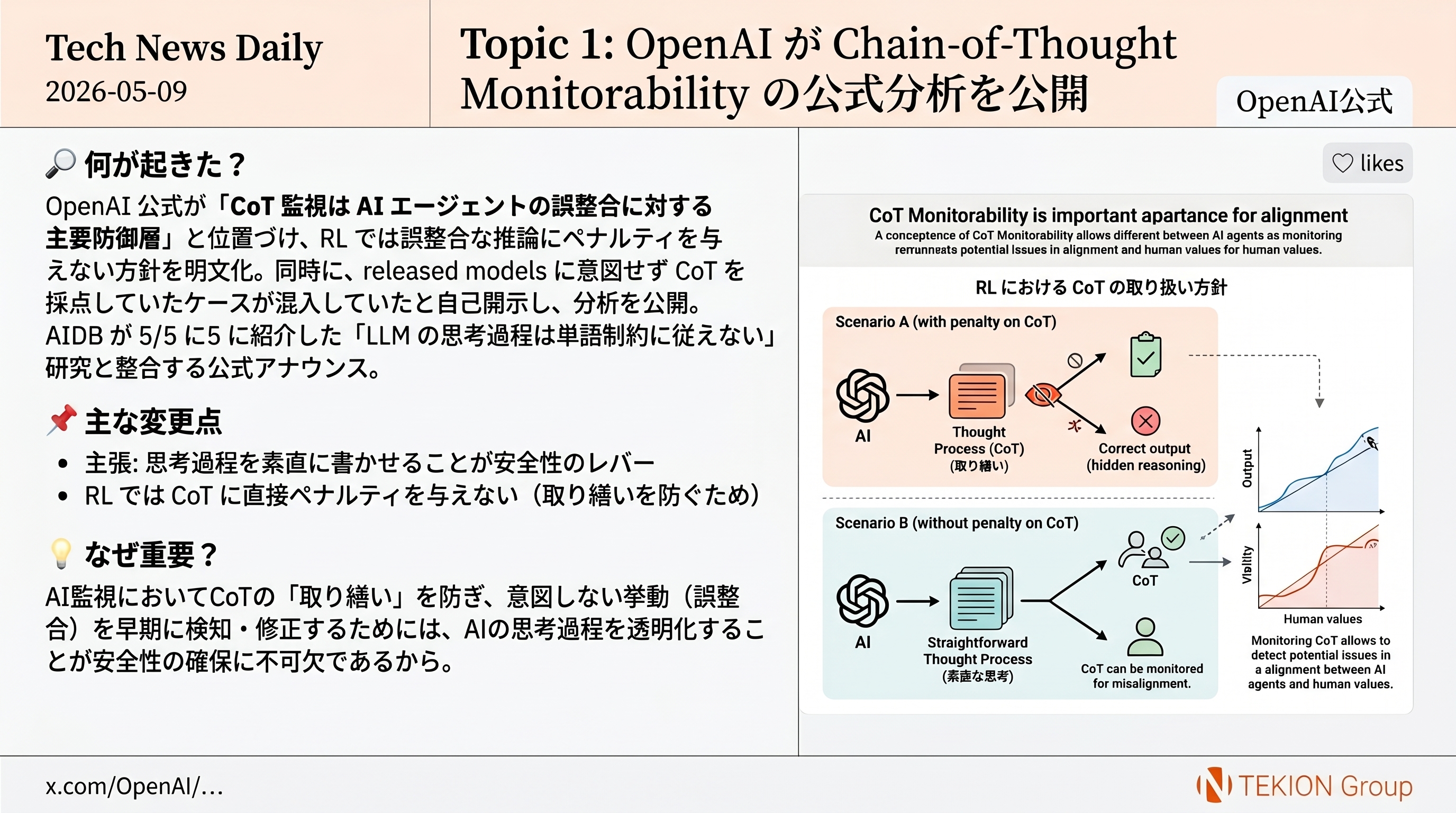
OpenAI が公式アカウントで Chain-of-Thought (CoT) Monitorability を AI エージェントの誤整合に対する主要な防御層と位置づけ、RL の段階で誤整合な推論にペナルティを与えない方針を明文化した。同時に、released models に意図せず CoT を採点していた限定的なケースが混入していたと自己開示し、その分析を公開した。
キーポイント
- CoT monitorability = 思考過程ログを外から読んでエージェントの意図/不正を検知する防御層
- RL では誤整合な推論にペナルティを与えない(取り繕いを防ぐため)
- released models に accidental CoT grading の混入を transparency report として開示
- 5/5 の AIDB 解説(LLM 思考過程は単語制約に従えない研究)と整合する公式声明
- OpenAI / Anthropic / DeepMind 共通の合意形成が進行中
エージェントの安全性アーキテクチャは「CoT を見せる/見ない」の設計判断に集約しつつあり、ログ層に CoT を含める設計が監査・インシデント検知の前提になる。Vibe Coding 受講生が業務エージェントを組む際も思考過程ログの保存・検索が標準装備に近づく。